An Introduction to Topics
Topics are the core of the text analysis in Gavagai Explorer. They are basically the main subjects in your data. For instance, in a set of hotel reviews, subjects like hotel, staff, room, restaurant, etc. are usually among the main topics. In addition, there is usually another type of topics in the texts which are not related to a hotel in general but become a topic for one specific hotel because of the frequent mentioning by respondents. For example, if you have a data including hotel reviews and many of the respondents refer to many items in the hotel as complimentary items (e.g. a comb, chocolate, drinks in the restaurant, etc.) then "complimentary" becomes a topic in your project. On the other hand, if many of the respondents complain about a specific issue in the hotel; e.g. renovations, then that issue also becomes a topic in your project.
Each topic in Explorer has a name and it includes one or more terms. The topic name is a label assigned by the system or the user for referring to the topic, while the terms are the actual words (or sequences of words) from the data that the topic is composed of. Each term can be included in only one topic. We say a document includes a topic if it includes at least one of the terms in that topic. Then, the frequency of a topic is defined as the number of documents that include that topic, divided by the whole number of documents.
Explorer automatically finds the main topics in your data and makes it possible for you to revise them. When you run Explorer on a dataset for the first time, it shows you the 30 most frequent topics throughout all the texts.
For each topic, Explorer considers a specific area for that topic in both overview and detail panel. We refer to the overview and detail panels as simply the topic area. In addition, there is a section for each topic in the overview panel which includes the name of the topic, as well as some buttons and information. We refer to this box as topic box. Here you can see the topic box for the topic "Room" in a dataset of hotel reviews.

When you click on the topic name, its details will be shown in the detail panel to the right.
In the following, we explain the main elements in each topic and we guide you through revising them.
Terms in Explorer
An Introduction to Explorer's Language Capabilities
Paradigmatic Neighbors
Explorer searches for terms in your data with more complexity than a simple search engine. Let us explain by an example. Consider the word “income” in the following sentences:
Many people are dissatisfied with their income.
I can't get by on such a small income.
The company's gross income grew considerably this year.
The single most important measure of a company's profitability is net income.
Compensation is far below the market.
In the first two sentences, income has been referred to as a general term while in the two latter sentences the terms gross income and net income are specific types of income. In the last sentence, the word income is not present, but we have the word compensation which is a synonym of it. Words like income, net income, gross income and compensation are called paradigmatic neighbours. Paradigmatic neighbours are semantically related words which are used in text or speech for related objectives. Paradigmatic neighbours can be synonyms, like “income” and “compensation” in above examples. They can also be words that do not have same meanings but they are related in some way; e.g. “fork” and “spoon” which are both used for eating.
N-grams
An n-gram is a sequence of words which frequently appears in the same order in text or speech. Generally, it is important not to split n-grams as it might result in information loss. For instance, “water supply” is an n-gram consisting of two words “water” and “supply” while none of these words can define it individually. The word “San Francisco” is an n-gram which is different from both “San” and “Francisco”. Another capability of Explorer is to identify n-grams in your data and not split them. From now on, when we mention terms in this document we mean n-grams. The value of variable n is dependent on the corresponding language and it is usually between 1 and 3 or more.
Topic Terms
As mentioned, each topic can include one or more terms. Terms included in each topic are words that each can define that topic independently. Each term can belong to only one topic. You can find your topic terms, as well as suggestions for new terms and some more information in the detail panel. Only the 20 most frequent terms will be shown when the exploration results load. If there are more than 20 terms, you can see all of them by clicking "See all". If you quickly want to verify if a term is valid for a topic, you can do that by looking at text examples by hovering over a term and clicking on the appearing tooltip.
You can also look at text examples for your topic in a more detailed view by clicking "See examples". You will be presented with filtering options for sentiment, topic terms, and related topics. The examples and sentiments which are shown for a topic in the detail panel are derived from the selected filter for that topic. Click "Apply Filters" to update your results if you make any changes to the filters.
Synonyms
When the project is explored for the first time, the Gavagai Explorer uses its language resources and algorithms to automatically merge words that we consider as "synonyms" into the same topic and these synonyms are taken into consideration when performing the analysis. There are multiple reasons that terms can be considered "synonyms" and merged into the same topic
Static Synonyms
The Gavagai Explorer's living lexicon constantly looks for new words the it considers synonyms. Once it has identified words that are strongly related, a Gavagai administrator can mark these words as Synonyms so that they are included as part of the same topic during exploration for all users.
Collaborative Synonyms
The Gavagai Explorer also utilizes users' anonymized topic models to automatically automatically merge terms into the same topic. If a certain number of users individually and without knowledge of each other accept synonym suggestions that makes it more likely that those terms will automatically be included as part of the same topic for other users in the future. This never happens with a single accepted suggestion or even with several by a single account.
Morphological Synonyms
In most languages, there are several words that have the same root but have slight variation due to grammatical rules (such as "teachers" and "teacher"). This is especially true in certain languages such as Finnish and Croatian, in which there can be over 100 variants of the same word. In certain languages, the Gavagai Explorer also merges the morphological variants of words together into the same topic to ensure the exploration results are more accurate.
Topics with Sentiment Words
Sentiment words are words that have some inherent sentiment or emotion; for example, "good" or "horrible" are sentiment words since they are positive and negative words respectively.
While there are benefits to having "sentiment topics" (topics containting sentiment words), any sentiment results computed for these topics will be adversely skewed since the sentiment calculation algorithm does not include the topic terms themselves while checking for the sentiment words about the topic terms.
As a consequence, sentences such as "the house was nice", will receive a positivity score of 0 when sentiment analysis is performed for a topic containing the word "nice".
Since sentiment analysis plays an important part in the insights retrieved from Gavagai Explorer, sentiment words will never be automatically included in any topics created by the system. That being said, the Gavagai Explorer will always allow you to manually create topics which contain sentiment words, but the sentiment results of these topics may be skewed due the reasons listed above.
Topic Suggestions
For the terms included in a topic, Explorer automatically finds their paradigmatic neighbours and shows them to you as suggestions. You can see more suggested terms by clicking on the "Refresh" button. When you hover over a suggestion in the overview panel, a tooltip with frequency information will appear. You can see the examples of the texts including that suggestion by clicking on this tooltip. When you add new terms to your topic, Explorer updates the suggested terms list by adding new possible suggestions. Press "Refresh" to make them appear. The new suggestions are shown under the label "New suggestions".

Terms and suggestions are listed in descending order according to their number of mentions. This number is indicated in the tooltip you see when hovering over a word.
Adding and Removing Terms
Adding Terms
You can always expand your topics by adding new terms to them. To add terms, you can either click on suitable suggestions or write them manually in the search field. An auto-complete drop down menu presents terms from topics and related topics as candidates, and you can either select several options or add all of them at once. You are also able to add terms that do not show up as search candidates.
To see more suggestions, you can click on "Refresh" button.

Note that a term included in one topic might appear in the suggestions of another topic. For instance, consider the the topic "Income" including the terms “income”, “salary” and “salaries”.

Next, consider the topic "Compensation" including the terms “compensation” and “compensations”. Since the two words compensation and income can be used interchangeably in the same contexts, you see the term “compensation” as a suggestion for the topic "Income".

In this case, if you choose to accept compensation for the topic "Income", Explorer will merge the two topics automatically (read more about merging here). This is basically because the terms in each topic are assumed to be synonyms (so if two terms in two different groups are synonyms then all terms in that groups are synonyms). However, you can always choose to only move certain terms by clicking on the "+" next to them and cancelling the merging of topics.

In the figure below you can see the new topic "Income" after automatically merging the two topics. The topic "Compensation" will become disabled. The next time that you press "Explore", you will see the new statistics for the new topic "Income" and the topic "Compensation" will be removed from the list.

The full search feature of the auto-complete drop-down menu presents terms from the project that are not yet members of any topic. As you type your auto-complete term, the full search finds all terms and multi-word expressions that match. Beware, however, that the search only finds multi-word expressions that the Explorer system knows about. This means that you cannot search for expressions that are two words or more unless these have been recognized as multi-word expressions in the system. Here is an example: the multi-word expression "san francisco" is a valid search term since it is so prevalent in ordinary language that our system knows about it as such. On the other hand "daniel san" is perhaps not as common and therefore a search for those two words will not get a hit even if the project in fact contains one or more texts with those words in sequence. Why not allow the search to find any arbitrary sequence of words you might ask. Similarly to much of the Explorer's functionality in general, the full search feature is focused on finding the most important expressions as opposed to everything in detail. This design is a careful balance of utility and performance considerations. But remember, you are also able to manually add terms that do not show up as search candidates.
Removing Terms
You can remove terms from topics by clicking on the "X" next to them in the detail panel. When you remove a term, you might still see it in the list of suggestions of other topics and therefore you can add it to them. Note that when you remove a term from a topic, Explorer automatically pins that topic so that you would not lose the topic in the list of topics in case the topic becomes infrequent.

You can also ignore all terms in a topic from your analysis by clicking on the "Ignore topic" icon, or ignore a single term by entering it in the text box under "Ignored Terms" at the bottom of the overview panel.

When you ignore a term, Explorer ignores it in your analysis. However, note that texts including that term are still available for contributing to other topics.

Related topics
For each topic, Explorer finds words that are tightly connected to the terms in that topic, and shows them to you as "Related Topics". By tightly connected we mean words that appear together repeatedly and closely in the same sentences in different texts. For each topic, the list of related topics can be found in the detail panel. You can also find the occurrence statistics of each related topic with respect to that topic next to it. Related topics are ordered in the related topics list based on their frequency.
Related topics can give you a better understanding of the topics. For example, consider the topic "Noise" which is a frequent term in the hotel reviews data set. As you see, the topics "Room", "Elevators" and the term "outside" are tightly connected to this topic which means many respondents complain about different sources of unpleasant noise during their stay.

You can generate a "Rule-based topic" from any of these related topics by clicking the "Generate Rule-based topic" action. This new topic is configured to display texts that illustrate a connection between the primary topic and the related topic.
You can also quickly see examples that relate the primary topic and the related one by clicking the "See Examples" action. You'll be redirected to the main topic's "See examples" section, where the related topic's terms will be set as filters.

In the "See examples" section, for any subset of the set of terms and related topics, you can filter the texts examples that contain all the words in that subset. You only need to specify your search parameters to filter texts.

Sentiment Analysis
Gavagai Explorer applies word-based or lexical-based sentiment analysis principles to quantify the sentiments behind expressed opinions. In the detail panel, you can see the quantity of two basic sentiments for each topic or group; that are Negativity and Positivity (next figure). When you filter texts by selecting terms and related topics in the example section, the sentiment values will be updated as well. When you export the result of your analysis into Excel, you can see 8 sentiment values for each single text (see the sentiment section). You can also select one or multiple topics for sentiment analysis when you export. This will give the sentiment scores for your selected topics in the report (see Sentiments Per Topic). Moreover, you can model your own sentiments by using the Concept modeller and then Explorer will analyze your data for these Concepts (read more in Explorer Concept Modeller).

More about Sentiment Analysis in Explorer
Explorer performs two different types of sentiment analysis: new and classic sentiment analysis. Explorer selects the new sentiment algorithm by default. You can always switch to the classic sentiment algorithm in your account and projects settings. Explorer will strictly apply only one algorithm for an entire project. When you set an algorithm on account level, you must explore your project at least once to apply the new algorithm.
The classic sentiment algorithm performs a sentence level sentiment analysis for each topic. The new algorithm performs a topic level sentiment analysis for the topics. More on both of these algorithms in The Sentiment Analysis Algorithms that Determine the Score.
This difference is important when a sentence has different topics with different sentiments. If a sentence is so short and has only one topic: "The room is good", then using either the new or the classic algorithm will result in the same score.
The Sentiment Scoring System
The system's sentiment scoring gives a score for each Sentiment word used to describe a topic. Note, amplification words such as "very" increase the score. And negations such as "not" impact the score by neutralizing or even flipping the associated sentiment.
For example:
The room was good. Has a 1 for Sent: Positivity.
The room was really good. Has a 2 for Sent: Positivity.
The room was not good. Has a 1 for Sent: Negativity.
There are eight sentiment categories: Skepticism, Fear, Violence, Hate, Negativity, Love, Positivity, and Desire. The categories avoid ambiguity of sentiment scoring across different domains by not containing words that can be inside many categories. For example, "cheap" could have different sentiments. "X is cheap": This sentence is ambiguous. If X is beer, it is positive, if X is a wedding ring it is negative. If there is a domain-specific word that you believe should be in a certain sentimental category but that is not picked up by our algorithm, you can consider using a Sentiment Customization to include it in your sentiment analysis.
When a word from the eight categories such as Positivity, for example "nice", is used to describe a topic such as "Room" the sentiment score will be 1 for the topic "Room". The sentence, "The room was nice." would receive a 1 for Positivity, and 0 for the seven other sentiment categories. You can have a look at these scores in detail when exporting a report of your project; see Sentiments Per Topic for more.
The Sentiment Details
For each topic it's possible to see what terms are contributing to the sentiment of each topic, and the occurrence of that sentiment term within the topic. When clicking a sentiment term, you will see examples where that term appears. For flipped terms there is an icon next to the term. In the example below, all texts with e.g. "not clean" will contribute to Negativity.

The Sentiment Graphs in the Web Application
In the web application, sentiments are shown in the detail panel and are presented as a percentage breakdown and also in absolute values. We see the sentiments Negativity and Positivity in this bar, as well as what we define as Neutral sentiment. This sentiment percentage bar is calculated by using the topic that the percentage bar is referring to. All the topic's Positivity and Negativity scores are summed and every text that contains neither of these sentiments is considered neutral. For each sentiment category this sum can be found next to its name above the sentiment bar. Then, each of the scores are divided by the sum to return a percentage. To see the text examples which are relevant to one specific sentiment category, you can click on its respective section in the sentiment bar.

It's also possible to change basic sentiments in the bar to any other sentiment Gavagai Explorer supports: Love, Hate, Violence, Desire, Fear, and Skepticism. You can also turn off the Neutral sentiment that is calculated and shown - this can be adjusted in your Project Settings or Account Settings. See Project Settings - Sentiments.

The sentiments are also detailed in the Dashboard, represented in a circular chart.
The Sentiment Analysis Algorithm that Determine the Score
Consider the following text uploaded to The Explorer:
- The room was good and the staff are bad.
The text includes two different topics and for each topic there is a different opinion. The sentiment algorithm will interpret and calculate the sentiment scores for each individual topic. For instance, in the current scenario, the "Room" topic would be assigned a positivity score of 1, while the "Staff" topic would receive a negativity score of 1.
It is important to note that not all topics are relevant for sentiment analysis. Explorer will only conduct sentiment analysis for topics (or topic terms) that are not sentiment terms in themselves.
Consider the sentence "The room is nice". If we ask what is the expressed opinion about "room" in this sentence, one can say it is positive, it is described as "nice". Now suppose that instead of "room" we focus on "nice" as a topic. Does it make sense to ask "what is the expressed opinion about "nice" in this sentence"? The answer is no. In fact, "nice" is not a focus topic in this sentence. The sentence is describing "room" and not "nice". "Nice" is the word by which the sentence expresses an opinion about "room". This is the reason behind why we do not perform sentiment analysis for a sentiment terms.
Sentiment Analysis and the Text Examples in the Web Application
In the example section of the detail panel, Explorer shows examples of texts which are included in the topics. These texts are examples featuring the terms of the topics selected in the search filter. At the top of each example area, Explorer shows sentence(s) that feature the topic terms. To the right hand side of each sentence, their topic-related sentiments are shown by colored circles, where each color shows the same sentiment as in the sentiment bar. You can see the complete texts by clicking on "Show original text" at the bottom right corner of the examples. Here you can also see the sentiments found in the entire text (not specific to the particular topics). Note that Explorer only shows those sentiments that you have chosen in your project.
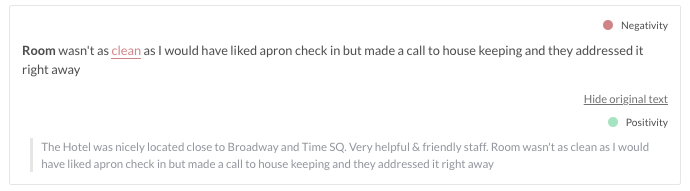
You can view the text examples corresponding to each sentiment by clicking the sentiment in the sentiment bar or in the sentiment legend; these examples are filtered by the selected sentiment. If you would like to see all examples matching the topic terms, you can clear the sentiment filter by pressing on "Clear sentiment".
Sentiment re-classification
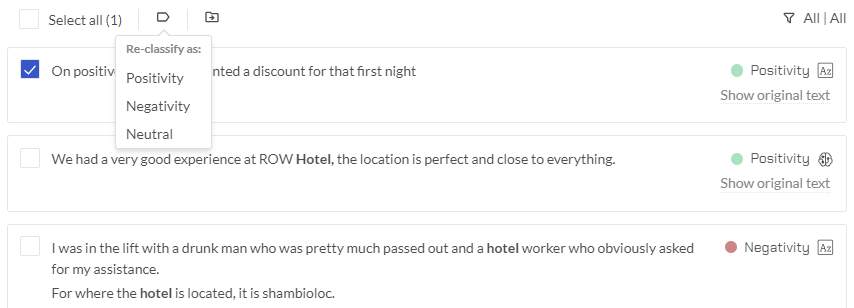
If you come across a text example that has been categorized with a certain sentiment, and you wish to modify that classification, it is possible to reclassify the sentiment to any other available sentiment for that particular project. It is important to note that this reclassification is specific to the topic in question and is not shared with others.
Topic re-classification

You can re-classify a text to a different topic, copy it or remove it from its initial classification. This functionality proves particularly useful when examining examples under the "Unclassified" category, enabling you to fine-tune and enhance the accuracy of your classifications.
When it comes to sentiment analysis, it's important to note that if a sentiment text has been re-classified, any previous sentiment re-classification will be lost when the topic is re-classified. This ensures that your sentiment analysis accurately reflects the latest classification decisions.
Another aspect to consider is that topics without any associated example texts will still be displayed and accessible during exploration. This allows you to maintain a comprehensive view of all topics, even if they currently lack representative examples.
Furthermore, in situations where all associated topics have been removed, example texts will be displayed under the "Unclassified" category.
Finally, note that you can only move a text to a pinned topic.
Overall Sentiment of the Project
In the Project Summary, we have the overall sentiment of the project shown in a colorful bar. This feature is dependant on your active sentiments, your sentiment settings and if neutral sentiment is activated or not. Based on these settings and the contribution of each verbatim to each sentiment, the percentage of each sentiment is calculated for all verbatims.

You can also see text examples by clicking on "See examples", and you can filter the examples for a specific sentiment by clicking on the related color on the sentiment bar.

More about n-grams in Explorer
Now that you have learned about topics, topic terms, and sentiment analysis, it is worth learning a bit more about n-grams in Explorer as well. As mentioned before, n-grams are topic terms including multiple words, for example "San Francisco". Explorer identifies n-grams in your data and shows them to you as topics if they are frequent enough. You can also add n-grams to your topics manually. The most important characteristics of the n-grams is that they are treated as one single entity, and therefore, the terms included in an n-gram cannot contribute to topics individually. This is the case for both topic counts and sentiment analysis. As an example, suppose that you have an n-gram "junk food". Also assume that you have a topic "Food" which includes "food" as a topic term but not "junk food" as a topic term. Now for the sentence "I don"t like junk food at all", for Explorer the topic "Food" is not assigned to this sentence because of "junk food" being a bi-gram.
Auto-Add Terms in Explorer
When working with topics you may notice that there could be several multiword expression n-grams containing a general topic term you are interested in (for example, you could be interested in the general topic term "food" and the Gavagai Explorer detects n-grams "fast food", "junk food" and "food delivery") and you may want to include all variants of the general topic term in the topic. One way of achieving this is to utilize the search functionality and selecting all variants of the term. The drawback of doing this is that once data is appended to the project and new n-grams are detected in the data, the same process must be repeated for all such general terms if you wish to keep the topic definition up-to-date with the current data.
Alternatively, you can utilize the "Auto-add terms" feature:

When you add a term in the "Auto-add terms" section of the topic, Explorer will automatically add any n-grams containing this term to the topic when the project is explored. Any n-gram which matches an Auto-add Term but which is already part of another topic will, however, not be included in the topic. Once a project is explored after data is appended to it, newly detected n-grams in the new dataset matching any Auto-add terms will be added to the appropriate topics and an email notification will be sent specifying the terms which were added to the topics.
If there are terms which have automatically been added to a topic as part of an Auto-add term, and you would like to exclude one or more of these terms from the topic (for example if you have an Auto-add term "food" and you want to exclude the automatically added n-gram "cat food" from the topic), you can always click the terms, as usual, to remove them. However, this term will now be added to the project's "Ignored terms" to ensure that the term is not automatically re-added to the topic. If you want this term added another topic instead, remove the term from the project's "Ignored terms" and then add the term to the other topic.